Спасибо. Почитал, действительно не баг, а фича. Просто раньше на настолько простых примерах не сталкивался.
Некорректная арифметика (вычитание), Excel 2013 с погрешностью считает вычитание с двузначной точностью
Некорректная арифметика (вычитание), Excel 2013 с погрешностью считает вычитание с двузначной точностью
Объединить по заголовку, объединить текст в ячейках строки, удовлетворяющих заголовку
|
13.11.2024 15:11:10
Да, столбцов много, спасибо большое, МатросНаЗебре!
Изменено: - 13.11.2024 15:13:11
|
|
|
|
|
Объединить по заголовку, объединить текст в ячейках строки, удовлетворяющих заголовку
Ряд данных в ячейке, вытащить данные из ряда с разделителями в ячейке
|
30.10.2024 14:33:03
Добавил в эксельку нужные результаты, посчитанные руками, с формулами, чтобы было понятно, какие значения суммируются.
МатросНаЗебре, спасибо за решение, но я к нему обращусь, если не найду чего-то более воспроизводимого. Сам-то я разберусь, а вот с объяснениями будет тяжело Sanja, спасибо за вариант, доберусь до нового Экселя, потестирую. |
|
|
|
|
Ряд данных в ячейке, вытащить данные из ряда с разделителями в ячейке
Ряд данных в ячейке, вытащить данные из ряда с разделителями в ячейке
Сцепить по произвольному количеству условий, Задача в чем-то обратная поискпозу сцепленных столбцов (ВПР по нескольким условиям)
|
21.09.2023 12:37:28
Ігор Гончаренко, Спасибо! А есть ли аналог для 2013?
|
|
|
|
|
Сцепить по произвольному количеству условий, Задача в чем-то обратная поискпозу сцепленных столбцов (ВПР по нескольким условиям)
Поиск по слову, Поиск во фразе слова из списка и вставка его и следующего за ним
|
13.09.2023 16:56:15
Павел \Ʌ/, спасибо за решение, работает, как нужно!
МатросНаЗебре, я прошу прощения, не стал полностью копировать и перебирать все переменные, так как у коллеги решение вышло короче. Msi2102, преклоняюсь перед умами, которые вертят формулами на таком уровне. Sanja, мне всегда нравится, как коротко и ступенчато выглядят макросы, но к сожалению из-за отсутствия пересылаемости не могу их использовать. Бахтиёр, спасибо, в 365 есть очень удобные и простые формулы, жалко перейти не вариант. Единственное, я использовал результат этой конструкции внутри функции Гиперссылка и получил ошибку "Не удается открыть указанный файл", хотя ссылка была на поиск Яндекса получившейся фразы. Решил просто вставкой текста первой половины адреса ссылки (адрес яндекса без текста запроса, который ищет рассматриваемая в теме конструкция) в виде текстовой строки в формулу вместо ссылки на ячейку с этой первой половиной ссылки. Это странно, так как конструкцию с Гиперссылкой использовал ранее в другой таблице, но без формулы: внутри гиперссылки собирались первая половина ссылки, затем тип и наименование водного объекта, всё напрямую из ячеек, - и ошибка не появлялась. Спасибо всем большое, коллеги! |
|
|
|
|
Поиск по слову, Поиск во фразе слова из списка и вставка его и следующего за ним
Равномерное распределение сумм по годам
|
28.08.2023 10:27:47
Ігор Гончаренко, спасибо, интересное решение! Я не стану даже вдаваться в перемножение неравенств, так как не пойму, но мне хотелось бы знать, откуда появился столбик 2023 и в чем смысл значений в нем.
Апд: Всё понял, заглянул в Солвер)
Изменено: - 28.08.2023 11:01:59
|
|
|
|
|
Равномерное распределение сумм по годам
Равномерное распределение сумм по годам
|
27.08.2023 00:02:17
Ігор Гончаренко, спасибо за внимание, тем не менее. Может быть, кто-нибудь еще заскочит в тему, ткнет меня в правильное русло.
|
|
|
|
|
Равномерное распределение сумм по годам
|
26.08.2023 23:46:36
Ігор Гончаренко, изменил, посмотрите пожалуйста. Прям проблема какая-то картинки вставить. На всякий случай как файлы вставил.
|
|
|
|
|
Равномерное распределение сумм по годам
|
26.08.2023 23:32:52
Ігор Гончаренко, Спасибо за терпение! Вот два примера (файл тот же, я просто перенес из плановой стоимости значения в искомую область):
1) Нулевой вариант, который я описывал выше, когда в 1 год планирования из 7 (2024) начинается первый год проектирования ($ПИР_1) у всех объектов одновременно: 2) Попытался немного разбить вручную (тоже перетаскиванием ячеек) - стало получше, но не оптимально и не масштабируется:
Изменено: - 26.08.2023 23:45:18
|
|
|
|
|
Равномерное распределение сумм по годам
|
26.08.2023 22:39:18
Ігор Гончаренко, объем финансирования по каждому объекту известен и проставлен в соответствующих столбцах - на ПИР 2 года (2 столбца) и на СМР 4 столбца, где заполнено 2-4 года (по объему).
Я просто не знаю, как понятно изложить задачу: нужно, чтобы по годам суммы затрат на все объекты, общий бюджет, были как можно более близки по значению. Как пример, можно не менять начало ни одного из объектов, оставить начало всех из них на первый год, но тогда 7 год (2030) будет пустой, 5 и 6 год будут минимальными из-за 3х и 4х-летних мероприятий, объем финансирования на 3-4 годы будет сравнительно большим. Ну, и косвенно проектирование пострадает - менее эффективно одновременно всё проектировать в 1-2 годах, чем если размазать проектирование частично на 1-2, 2-3, 3-4 и даже 4-5 годы (для двухлетних мероприятий остается 6-7 год на СМР). Логика, как мне кажется, самая эффективная - это размазать на 3-7 годы (2026-2030) СМР, чтобы финансирование было равномерным, а потом уже перед началом СМР повтыкать 2х-летние ПИРы, так как они меньше по стоимости и сильно баланс (равномерность) не поломают. А вот как это сделать в Экселе - для меня большой секрет. Как-то наверное надо сводную таблицу заставить считать суммы по годам и выровнять по ним годы финансирования строительства... Либо я даже согласен, если меня ткнут на нормальное названия такого типа задач, по-любому размазывание по годам бюджета должно быть очень популярно. Я попытался как-то "транспортную задачу" натянуть на это, но вроде не подходит. Так что, не знаю даже, куда гуглить =( |
|
|
|
|
Равномерное распределение сумм по годам
|
25.08.2023 20:30:06
Ігор Гончаренко, разделить я могу, но каждый объект разный по длительности и стоимости. И стоимость эта распределена неравномерно как между СМР и ПИР, так и внутри СМР.
Некоторые объекты, допустим можно начать в первый год, какие-то во второй, какие-то - в третий. Если их начинать сразу - расходы будут неравномерными. |
|
|
|
|
Равномерное распределение сумм по годам
ОБЪЕДИНИТЬ в произвольном порядке, Усовершенствование примера из приема "3 способа склеить текст из нескольких ячеек"
|
19.08.2023 23:46:51
Alien Sphinx, спасибо за пример, когда-нибудь я смогу (наверное) попробовать массивные формулы из 365, а пока в копилочку. Выглядит достаточно элегантно, надо признать.
DAB, ну нет же. формула уже написана, нужно не ячейки отдельные сцеплять, а все ячейки внутри массива. "Сцепить" это не может, указание вручную элементов это совсем не то, можно и просто & использовать тогда уж. Подходит именно "Объединить", которая весь массив ячеек склеивает. Только мне нужно, чтобы ячейки склеивались не по порядку (A1&A2&A3...&A6), а в произвольной последовательности: когда A2&A5&A3...&A1, когда A3&A1&A4...&A2, когда еще как. Суть именно в рандоме. |
|
|
|
|
ОБЪЕДИНИТЬ в произвольном порядке, Усовершенствование примера из приема "3 способа склеить текст из нескольких ячеек"
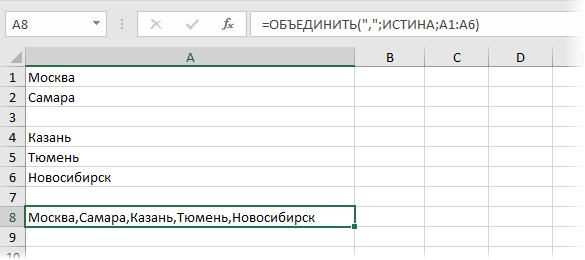
Слияние текстовых диапазонов, оно же слияние списков, оно же консолидация текста
Дублирование текстового диапазона, оно же копирование списков, оно же перенос текста
|
26.03.2022 17:13:09
В общем, поэкспериментировав, понял 2 момента:
1) некоторые формулы "работают", если ячейки исходной таблицы и итоговой находятся на одной строке. Может внезапно возникнуть вопрос при размещении итогов в другом месте/листе; 2) как новичка, смущают "пробелы, которые не пробелы" - постарался учесть. В итоге, к чему пришёл:
Единственный вопрос, который остается - автоподстройка размера итогового диапазона под уменьшение/увеличение исходного. Может быть, это со СМЕЩем работает, подскажет кто? |
|||
|
|
|
Дублирование текстового диапазона, оно же копирование списков, оно же перенос текста
"Сохранить как...." меняет имя файла перед сохранением (дописывает Копия)
|
17.03.2022 19:15:12
Ловил похожий глюк на Ворде. Обратил внимание, что дописывается Копия, а не (1) и пр. Также в Ворде создается файл другого расширения. И старой даты - то есть, со временем создания, когда исходный файл был открыт, до редактирования, а после редактирования сохраняется файл с оригинальным именем и датой после редактирования.
Решил вопрос появления файла так: Файл - Параметры - Дополнительно - раздел Сохранение - убрать галочку Всегда создавать резервную копию. Не знаю, поможет ли здесь. |
|
|
|
|
Слияние текстовых диапазонов, оно же слияние списков, оно же консолидация текста
|
17.03.2022 15:04:20
jakim, спасибо, сохраню себе на случай необходимости PQ.
БМВ, благодарю за мегаформулу, буду пытаться ее разгрызть. Всегда поражался способности людей создавать такие комплексные решения! UPD: До конца смысла всей конструкции не докопался, но решил провести тест. Две формулы показывают разные результаты (в первой почему-то третье значение второго диапазона ошибочно). Также итоговый диапазон увеличивается только на одно значение, остальное игнорируется.
Изменено: - 18.03.2022 01:04:28
|
|
|
|
|
Дублирование текстового диапазона, оно же копирование списков, оно же перенос текста
|
17.03.2022 00:37:23
Добрый день! Нужно банально копировать один диапазон (Столбец1) в другой (Столбец2) без объединений и прочих действий. Просто: в одну таблицу пишем, в другой отображается копия, которая автоматически меняется, увеличивается и уменьшается в зависимости от текста в столбце. Из доступного к моему пониманию собрал так:
В целом работает, только диапазон не растягивает. Нашел на форуме семилетней давности с использованием АГРЕГАТ, но не смог понять, как это реализовать у себя, и смысл/плюшки метода в целом. Прошу: 1) подсказать более элегантный вариант; 2) пояснить, как сюда пристроить Агрегат, и есть ли смысл 3) подсказать, как (можно ли) сделать автоматическое изменение размеров второго диапазона. Планирую также экспорт формул в Гугл Таблицы, поэтому прошу без макросов и PowerQuery. Также прошу без формул LET и ПОСЛЕД (SEQUENCE), если возможно. |
|||
|
|
|
Слияние текстовых диапазонов, оно же слияние списков, оно же консолидация текста
|
17.03.2022 00:31:21
Добрый день! Есть три столбца с текстом (допустим, в разных умных таблицах, но в одном файле). Значения в них будут добавляться и могут удаляться, поэтому ссылки нужны не на ячейки, а на диапазоны (Таблица1[Столбец1]…). В таблице Таблица4[Свод] нужно вставить все три диапазона текстовых ячеек один за другим. Переформирование сводного диапазона происходит по мере удаления/добавления текста в исходных столбцах 1-3. В своде вручную вставленный результат, нужна формула. Консолидация, понятное дело, не подходит. Гугл находит либо по числам, либо сцепку текста в одной строке. Форум также просмотрел, но ничего удовлетворительного найти не смог. Хотелось бы, конечно «Таблица1[Столбец1]+Таблица2[Столбец2]+Таблица3[Столбец3]», но жизнь простой не бывает =))) Планирую также экспорт формул в Гугл Таблицы, поэтому прошу без макросов и PowerQuery. Также прошу без формул LET и ПОСЛЕД (SEQUENCE), если возможно. |
|
|
|
|
Последняя серия значений и количество серий, Если диапазон изменяется по датам
|
13.11.2021 12:35:29
, спасибо за интересный вариант, но от растягиваемых диапазонов я отказываться не хочу, тем более что предлагаемая формула также не проходит проверку на заполнение единицами. Я так понял, что если все значения диапазона равны 1, то это единственный логически возможный вариант, когда у Просмотра отсутствует даже одна единица среди #/DIV!'ов, которую функция могла бы взять до искомой двойки. Поэтому для данного варианта я ввел проверку на ошибку и поставил строку начала повторений, если массив занят целиком:
, также спасибо зя интересный вариант. Эта конструкция Просмотра мне вообще кажется космической, так как я не понимаю, как диапазон может быть отрицательным (перед ним стоит минус). Тем не менее, доп построения меня не устроили, и я решил поискать решение, которое выводило бы диапазоны единичек, которые можно было бы поделить на 7 и отсеять меньшие 1. Наткнулся на формулу , но вместо Макса использовал Суммпроизв по условию >=1, а потом округлил вниз.
Кстати, обратил внимание, что в формулах из присутствует интересная защита от дурака: при введении в пустые клетки нулей они продолжают считать корректно, в отличие от последующих, в том числе и моей.
Изменено: - 13.11.2021 12:43:51
|
|||||
|
|
|
Последняя серия значений и количество серий, Если диапазон изменяется по датам
|
11.11.2021 02:46:52
, исследовав вашу красивую формулу, привел ее к общему виду, которое соответствует условию задачи строго.
Поскольку следим мы за выполнением не с 22.09 (B2), а с 01.10 (B11, оно же $G$2), и не по железное B50, а по гибкое "сегодня" (оно же $G$6), то диапазон в столбце у нас не B2:B50, a скользящий:
Таким образом, преобразовав вашу элегантную, но конкретную, формулу моими усложнениями, получаем формулу, которая учитывает условия задачи в полной мере:
Для более общего случая в логике условия ссылку на "как бы сегодняшний" день $G$6 можно заменить просто функцией Сегодня(). Еще раз спасибо, что помогли разобраться. UPD: Нагородил я, конечно, нормально, но при тестировании выяснил, что если все ячейки в отслеживаемом диапазоне B11:B50 равны 1, то появляется ошибка #Н/Д. Причем, в изначальной формуле с фиксированными диапазонами (как у БМВ и Бахтиёра) ошибки нет и всё считается корректно. Всё, пойду спать Х_х
Изменено: - 11.11.2021 03:22:19
|
|||||||
|
|
|
