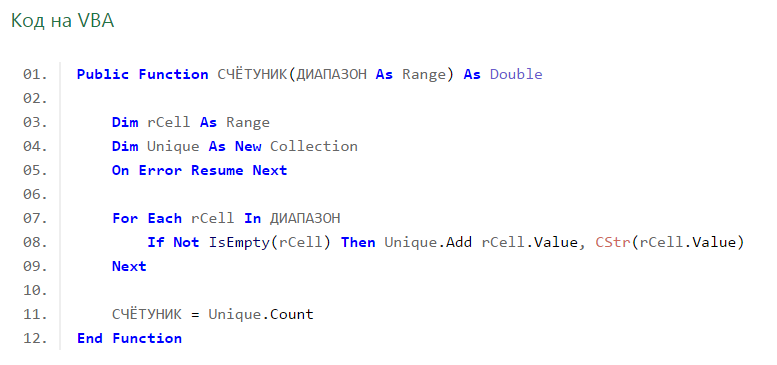
Приветствую.
Цель: подсчитать количество уникальных значений в ячейках, отобранных с помощью фильтра (или нескольких).
Пример во вложении, поиск уникальных значений осуществляется в столбце "В". Для подсчёта используется следующая формула:
=СУММПРОИЗВ((ЧАСТОТА(ПОИСКПОЗ(B2:B10&"";B2:B10&"";0);ПОИСКПОЗ(B2:B10&"";B2:B10&"";0))>0)*ПРОМЕЖУТОЧНЫЕ.ИТОГИ(3;СМЕЩ(A2;СТРОКА(A2:A11)-СТРОКА(A2);)))
Работает хорошо, за исключением одной детали: при отдельных условиях фильтрации в столбце "D" выдаёт ложный результат. Во вложенном файле попробуйте в этом столбце отфильтровать ячейки по критерию "сдан" - результат будет 2 (вместо 3).
Насколько понял, эта ошибка связана с тем, что формула работает следующим образом:
- ячейки просматриваются сверху вниз
- в качестве уникального учитывается первое найденное среди повторяющихся значений
- если ячейка, содержащая такое значение, скрывается в результате фильтрации, формула выдаёт 0 - в том числе, и в случаях, когда остаются видимыми остальные повторяющиеся значения
На примере из вложения:
- значение "5А" встречается в ячейках "В3", "В7", "В10"
- в качестве уникального учитывается значение в ячейке "В3"
- если в столбце "D" фильтровать по критерию "не сдан", формула выдаст верный результат, т. к. ячейка "В3" осталась видимой
- если в столбце "D" фильтровать по критерию "сдан", формула выдаст неверный результат, т. к. ячейка "В3" перестала быть видимой
Можно ли как-то исправить недостаток имеющейся формулы? Если да, что именно следует изменить. Если нет, подскажите, пожалуйста, какую формулу можно использовать для решения вопроса..
Цель: подсчитать количество уникальных значений в ячейках, отобранных с помощью фильтра (или нескольких).
Пример во вложении, поиск уникальных значений осуществляется в столбце "В". Для подсчёта используется следующая формула:
=СУММПРОИЗВ((ЧАСТОТА(ПОИСКПОЗ(B2:B10&"";B2:B10&"";0);ПОИСКПОЗ(B2:B10&"";B2:B10&"";0))>0)*ПРОМЕЖУТОЧНЫЕ.ИТОГИ(3;СМЕЩ(A2;СТРОКА(A2:A11)-СТРОКА(A2);)))
Работает хорошо, за исключением одной детали: при отдельных условиях фильтрации в столбце "D" выдаёт ложный результат. Во вложенном файле попробуйте в этом столбце отфильтровать ячейки по критерию "сдан" - результат будет 2 (вместо 3).
Насколько понял, эта ошибка связана с тем, что формула работает следующим образом:
- ячейки просматриваются сверху вниз
- в качестве уникального учитывается первое найденное среди повторяющихся значений
- если ячейка, содержащая такое значение, скрывается в результате фильтрации, формула выдаёт 0 - в том числе, и в случаях, когда остаются видимыми остальные повторяющиеся значения
На примере из вложения:
- значение "5А" встречается в ячейках "В3", "В7", "В10"
- в качестве уникального учитывается значение в ячейке "В3"
- если в столбце "D" фильтровать по критерию "не сдан", формула выдаст верный результат, т. к. ячейка "В3" осталась видимой
- если в столбце "D" фильтровать по критерию "сдан", формула выдаст неверный результат, т. к. ячейка "В3" перестала быть видимой
Можно ли как-то исправить недостаток имеющейся формулы? Если да, что именно следует изменить. Если нет, подскажите, пожалуйста, какую формулу можно использовать для решения вопроса..
Изменено: - 08.05.2017 13:21:57